
コラム
![]() 2026-01-15
2026-01-15
データマイニングとは?分析手法や手順、活用例もあわせてご紹介

データマイニングとは、膨大なデータから隠れたパターンや法則性を見つけ出し、ビジネスに有用な「知見」へと変換する分析手法です。統計学を用いて、これまで経験や勘に頼っていた判断を可視化し、客観的な根拠に基づく意思決定を実現します。本記事では、データマイニングの基礎知識や活用メリット、ビジネスへの具体的な導入方法について解説します。
目次
データマイニングの基本概念と機械学習との違い
ここでは、データマイニングの目的と、機械学習との関係について説明します。
データマイニングの目的と効果

データマイニングは、「マイニング(採掘)」という言葉の通り膨大なデータという「鉱山」から、ビジネスに役立つ「黄金(知識)」を掘り当てるプロセスを指します。
重要なのは、目的が「データの収集」ではなく、蓄積されたデータの中から「価値ある法則(パターン)」を見つけ出すことにある点です。
【具体的な活用例】
・売上分析:一緒に買われやすい商品の組み合わせを発見する
・顧客分析: 退会・離反の予兆がある顧客の特徴を特定する
・設備管理: 稼働ログから機械故障の前兆パターンを検知する
統計学や最新の解析技術を用いて「単なるデータ」を「価値ある知識」へと昇華させ、意思決定を支えることができます。
データマイニングで得られるもの
データマイニングを実施することで、「DIKWモデル」と呼ばれる知見を得ることができ、それぞれ下記の4段階に分類されます。
・データ(Data):データベースなどから収集されたままのデータ
・情報(Information):分析や集計が行われたデータ
・知識(Knowledge): 情報から得られる傾向や知見
・知恵(Wisdom): 知識を基に、状況判断や意思決定を行い、行動につなげられる状態
段階が進めば進むほど、データの価値が高くなるのが特徴です。
データマイニングと機械学習の関係
データマイニングと機械学習は非常に近い領域ですが、狙いには次のような違いがあります。
・データマイニング:収集されたデータの中から、人間の意思決定に役立つ「知識」や「ルール」を発見することが主目的。「なぜそうなるのか」「どんな傾向があるのか」を理解し、ビジネスで効果を発揮することに重きを置く
・機械学習:発見されたパターンをもとに、コンピューター(AI)が自動で予測・分類を実施するモデルを構築し、繰り返し使えるようにすることが主目的。スコアリングやリアルタイム判定など、オペレーションへの組み込みに強みを持つ
実務では「データマイニングによる知見の発見」から「機械学習モデルの実装」へと繋げ、成果を最大化する流れが一般的です。
データマイニングのプロセス
データマイニングプロジェクトを進める際には、業界標準のプロセスモデルであるCRISP-DM(Cross-Industry Standard Process for Data Mining)がよく使われます。
データマイニングのフレームワークの中でもツールや業種に依存しない汎用的な枠組みで、主に以下のフェーズで構成されます。
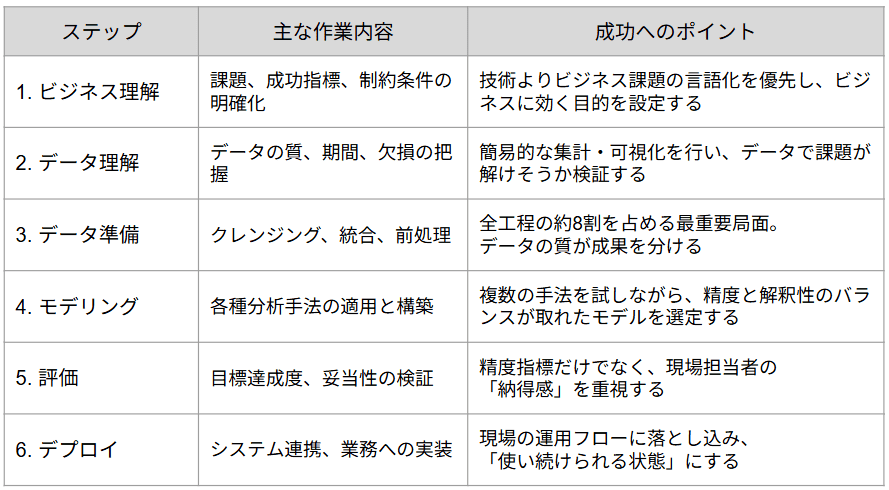
1.ビジネス理解

データマイニングの最初のステップは、技術ではなくビジネスの理解です。具体的には、以下の項目を整理します。
・解決したい課題は何か(例:解約率の低減、在庫の最適化、与信精度向上など)
・成功指標は何か(例:解約率○%改善、利益率○ポイント向上など)
・制約条件や利用可能なデータはどこまでか
これらについて、現場や経営層との合意形成を通じて目的を定義します。ここが不明瞭だと、分析をしてもビジネス成果に繋がらず、コストだけを浪費する結果を招く可能性があるため注意が必要です。
2.データ理解

ビジネスの目的を定義した後は、実際に利用するデータを詳細に把握します。主に以下の点を確認し、データの性質を理解しましょう。
・データの概要把握: データ量、対象期間、項目数(変数)の確認
・データの品質チェック: 欠損値や異常値の有無、分布の偏りの確認
このプロセスでは、簡単な集計や可視化を行いながら「このデータで本当に定義したビジネス課題が解決できそうか」を検証します。データの不足や質の低さが判明した場合は、目的の再定義やデータの追加取得を検討することもあります。
3.データ準備

データマイニングにおいて最も工数がかかるのがこのフェーズです。実務ではプロジェクト全体の約8割を占めると言われるほど重要視されます。
主な作業は次の通りです。
・データクレンジング: 欠損値や異常値の補完・除外を行い、データの「ノイズ」を取り除く
・データの統合・突合: 複数のシステムやファイルに散在するデータを、分析可能な形に結合する
・前処理(加工): カテゴリ変数の変換やスケーリングなど、モデルが扱いやすい形式に変換する
この段階の質が最終的な分析精度を決定づけます。 手間を惜しまずデータの質を磨き上げることが、成功の鍵となります。
4.モデリング(分析)

準備したデータを用いて、目的に応じたデータマイニング手法を適用します。課題に合わせて、以下のようなアプローチを使い分けます。
・クラスタリング: 顧客を共通の特徴ごとにグループ化(セグメント分け)する
・アソシエーションルール: 商品の「併売ルール」など、項目間の意外な関連性を抽出する
・予測モデリング: ロジスティック回帰などを用い、解約や購入などの発生確率を数値化する
分析においては、単に予測精度が高いだけでなく「なぜその結果が出たのか」を人間が理解できるかも重要です。複数の手法を比較検討し、ビジネスでの活用に最適なモデルを選定しましょう。
5.評価

構築したモデルが、最初に設定したビジネス目標に対して十分な成果を出せるかを検証します。ここでは以下の多角的な視点で評価を行います。
・統計的評価: 精度・再現率・AUCなどの指標が基準を満たしているか、また「過学習(学習データに過剰適合し、未知のデータに通用しない状態)」に陥っていないかを確認する
・ビジネス的評価: 導き出されたルールや予測結果が、現場担当者から見て「実務感覚と乖離していないか」「納得感があり、施策に活かせるか」を判断する
この評価の結果、不十分と判断された場合は、再度データ準備やモデリングの工程に戻ることも想定されます。
6.デプロイ(業務への組み込み)

データマイニングの最終工程は、得られたモデルや知見を実際の業務フローに組み込むフェーズです。
具体的には以下のような形で活用します。
・可視化の定着: ダッシュボードやレポートを作成し、常に最新の知見を共有・配信する
・システム連携: 予測スコアをMA(マーケティングオートメーション)やCRMと連携し、アクションを自動化する
・業務改善の実行: 抽出されたルールを現場の運用ガイドラインに反映し、具体的な施策として定着させる
データマイニングは、分析結果を出すこと自体が目的ではありません。現場の業務に落とし込み、運用を継続してはじめて、利益向上やコスト削減といった真のビジネス成果を生み出します。
代表的なデータマイニング手法とビジネス活用例
データマイニングの手法は主に以下の3つです。
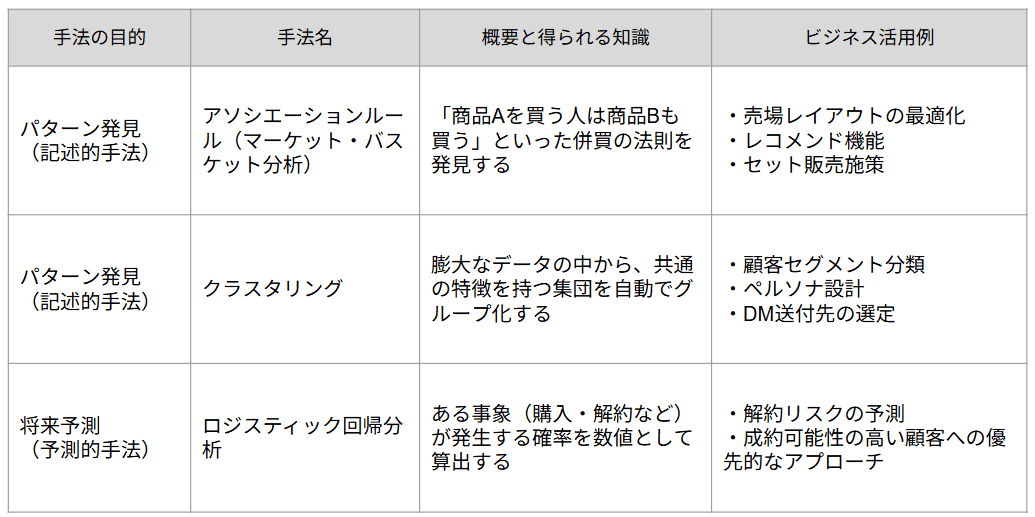
アソシエーションルール(マーケット・バスケット分析)
アソシエーションルールは、「商品Aを買った人は商品Bも買う」という併売の法則を見つける手法です。「もし〜なら〜」という形式でデータ間の意外な関連性を抽出します。
クラスタリング
クラスタリングは、似た特徴を持つデータ同士をグループ化する手法です。正解となるラベルがない状態から、データ自体の性質に基づいて「似たもの同士」を自動で分類します。
ロジスティック回帰分析
ロジスティック回帰分析とは、複数の要因から「購入する/しない」といった二者択一の結果が起こる確率を推定する手法です。 「どのような属性を持つ人が、どの程度の確率で行動を起こすのか」を数値で算出できるため、根拠に基づいた優先順位付けが可能になります。
プロセスマイニングとテキストマイニング
ここでは、データマイニングにおける「プロセスマイニング」と「テキストマイニング」について解説します。
プロセスマイニング

プロセスマイニングは、システムが自動的に記録しているイベントログ(業務の足跡)を分析し、実際の業務プロセスを可視化・改善する手法です。
例: 受注から出荷までの全工程において、想定外の迂回ルートや滞留が発生している箇所を特定する
活用: 業務のボトルネック解消、リードタイムの短縮、コンプライアンス遵守のチェック
テキストマイニング

テキストマイニングは、アンケートやSNS、問い合わせメールなどの「テキストデータ(非構造化データ)」を分解・数値化し、有益な知見を取り出す手法です。言葉の出現頻度や、それらが語られる際の感情(ポジティブ・ネガティブ)を分析します。
例: コールセンターに届く数万件の声から、新商品に対する共通の不満や期待の兆しを自動抽出する
活用: 顧客満足度の向上、SNSのトレンド分析、製品・サービスの品質改善
業界別の活用イメージ
データマイニングは、事実上すべての業界で活用可能です。大量のデータが蓄積される業務ほど、その恩恵を最大化できます。
代表的な活用イメージは以下の通りです。
・小売・EC:需要予測による在庫最適化、購入傾向に基づいたレコメンド、顧客セグメンテーション
・金融・保険:不正利用検知、与信スコアリング、リスク管理、解約予測
・製造:IoTデータを活用した設備の予知保全、不良要因の特定、サプライチェーン最適化
・通信・メディア:サービス解約率の低減、プランレコメンド、ネットワークトラフィックの負荷分析
成功のポイントと注意すべき課題
ここからは、データマイニングを確実に成果へつなげるために、押さえておくべきポイントと注意点を解説します。
成功のためのポイント

データマイニングを成功させるために意識すべきポイントは以下の通りです。
データウェアハウス(DWH)の構築
データマイニングにおける分析対象のデータは、多くの場合複数のシステムに分散しています。これを統合し、分析しやすい形で一元管理するのがDWH(データウェアハウス)です。
DWHが整備されていると、データマイニングだけでなくダッシュボードやレポーティングなどもスムーズになります。
データクレンジング体制
データマイニングにおいて欠損・重複・不整合などを取り除くデータクレンジングは、プロジェクトの成否を分ける最重要プロセスです。単発の作業で終わらせず、データの品質を維持・向上させるための運用ルールや専任体制を整備することが求められます。
目的に合ったツール選定
データマイニングツールは多種多様で、それぞれ特徴が異なります。「何を解決したいか」「誰が活用するか」を軸にツールを選定すると良いでしょう。
・ノーコード/ローコード型: 現場の担当者が直感的に分析を行う場合
・一気通貫型クラウドプラットフォーム: 準備からデプロイまでを効率化する場合
・BIツール: 可視化やレポーティングを重視する場合
注意すべき課題

データマイニングを活用する際には、次のような注意点もあります。
・専門スキルとリテラシー:統計・機械学習・プログラミングなどの知識が必要
・データの「質」への依存:誤ったデータからは誤った知見しか得られない
・相関と因果の混同:相関があるからといって、必ずしも原因・結果の関係とは限らない
・プライバシーと法令遵守:個人情報を扱う場合は、法規制や社内規定に沿った適切な管理が不可欠
データはあくまで意思決定を支える「材料」です。抽出された知見をどう活かすか、最終的な判断には人間の解釈と倫理観が欠かせません。
データマイニングはDX時代の「必須インフラ」
データマイニング関連ツールの市場は、今後も拡大が見込まれています。
ビッグデータやAI、IoTの進化により、センサーデータや行動ログといった多様なデータが膨大に蓄積されるようになりました。さらに、クラウド環境の進展やノーコードツールの普及により、専門家以外でも高度な分析基盤を容易に構築・活用できる環境が整っています。
今後のデータマイニングにおいては、従来の売上・顧客データに加え、人流や位置情報といった「これまで見逃されてきたデータ」を掛け合わせることで、新たなビジネス価値を創出していくことが求められます。
まさに、データマイニングはDX時代を勝ち抜くための「必須インフラ」と言えるでしょう。
データを活用しての戦略的意思決定ならロイヤリティ マーケティングへ
データマイニングは、膨大なデータからビジネスに役立つ知見を抽出し、それを「意思決定や業務改善の確かな根拠」へと変換するプロセスです。
以下のサイクルを回せるかどうかが、DX時代の競争力を大きく左右します。
・ビジネス課題を明確にする
・高品質なデータ基盤を整える
・適切な手法とツールを選び、実務プロセスに組み込む
・データに振り回されず、人間の判断と組み合わせて活用する
経験や勘だけに頼るのではなく、「データに裏付けられた客観的な判断」を組織の当たり前にするための鍵が、データマイニングにあると言えるでしょう。
しかし、データマイニングにおける高度なデータの取り扱いや、導き出された結果を正しくビジネスに翻訳するには、専門的な知見が不可欠です。社内でのリソース確保や育成が課題となっている場合には、外部の専門家を活用することも有効な選択肢です。
弊社では、実務経験豊富なデータアナリストが、お客様の状況に寄り添いながら、ヒアリングからデータ分析まで一貫して支援いたします。
データマイニングによるデータ活用で事業を次のステージへ進めたい方は、ぜひお気軽にご相談ください。

.jpg)

お気軽にお問い合わせください
詳しくお知りになりたい方はお問い合わせ