
コラム
![]() 2026-03-23
2026-03-23
クラスター分析とは|意味・種類・統計データの活用方法を徹底解説

クラスター分析とは、共通した特徴や傾向を持つ対象同士をグループ(クラスター)にまとめることで、データを分類し構造を明らかにする統計的な手法です。この記事では、クラスター分析の基礎から、分析を成功させるための手順まで徹底解説します。
目次
クラスター分析とは
クラスター分析とは、多様な特性を持つデータが集まった集団の中から、互いに似ているもの同士を「クラスター(集団・群れ)」に分類する統計方法の総称です。
あらかじめ「性別」や「年代」といった分類基準を人間が設定するのではなく、データそのものの類似性や特性に基づいて機械的にグルーピングする「教師なし学習」の代表的手法とされます。
分析者の思い込みや偏った判断を排除し、データの中に隠れた予期せぬパターンや新しいセグメントを発見・考察する方法としてクラスター分析が活用されます。
なお、弊社が取り扱っている「PERSPNA+」では、5万人のPonta会員×200設問以上のアンケートをもとに、性格や消費意識といった価値観クラスターを独自で構築しました。
専門性が高い金融や、嗜好性が影響しやすい食の領域では独自の価値観クラスターも用意しています。これからクラスター分析を活用したいとお考えの際は、下記のページから詳細をチェックしてみてください。
クラスター分析の重要性とわかること
現代のマーケティングにおいて、クラスター分析は顧客理解の深化や戦略立案に欠かせない手法となっています。
その最大のメリットは、数万件規模の複雑な生データを数個のクラスターに集約し、直感的に把握できる形へ可視化できる点にあります。この過程では、性別や年齢といったメーカー側の都合による分類ではなく、顧客の価値観や行動様式に基づいた「生活者視点」のセグメンテーションがなされるため、データの背後にある真の意味を考察することが可能です。
また、アルゴリズムを用いて機械的に類似度を測定することで分析者の先入観やバイアスを排除し、客観的な事実に基づいた発見を促します。こうして抽出された似通ったニーズを持つ集団に対し、最適なメッセージや商品を届けることで、One to Oneマーケティングの実践やターゲティングの最適化が実現します。
クラスター分析の種類と手法(アルゴリズム)
クラスター分析には大きく分けて「階層クラスター分析」と「非階層クラスター分析」の2種類があり、データの規模や目的に応じて活用されます。
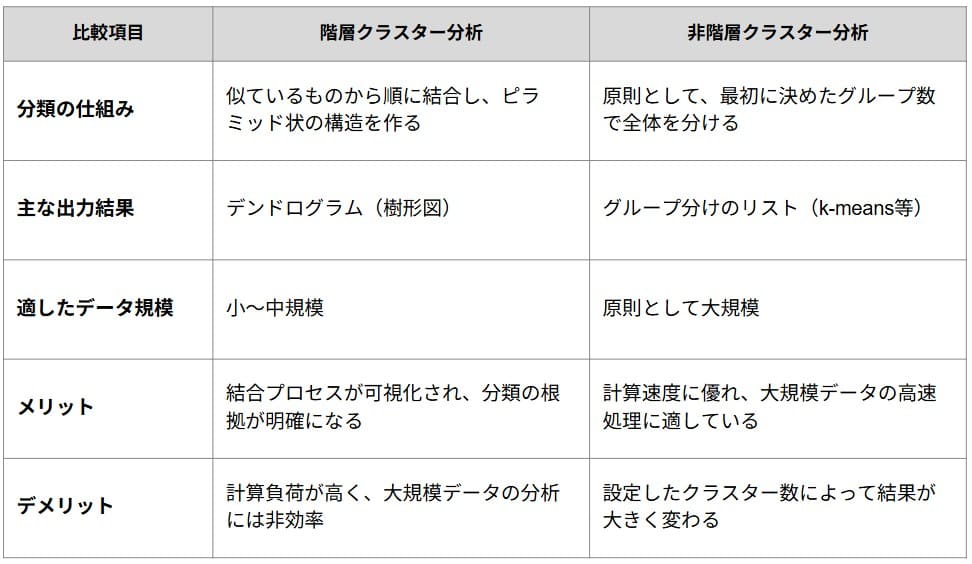
階層クラスター分析(Hierarchical Clustering)
階層クラスター分析は、最も似ている個体同士を順番に結合していき、最終的に一つの大きな集団にまとめる手法です。分析結果は「デンドログラム(樹形図)」として出力され、どの個体がどの程度の距離(類似度)で結合したのか、その過程を一目で把握できます。
階層クラスター分析の主要な手法
・ウォード法(Ward’s method): クラスターを結合する際、クラスター内の分散(情報損失)を最小化するようにまとめる。バランス良く分類でき、実務で最も推奨される高精度な手法。
・群平均法: 全データ間の距離の平均値をクラスター間の距離とする。考察時に外れ値の影響を受けにくく、結果が安定しやすいのが特徴。
・最近隣法(最短距離法): 最も近いデータ間の距離を基準とする。計算は容易だが、データが鎖状に繋がる「鎖効果(チェーン現象)」が起きやすいという注意点がある。
・最遠隔法(最長距離法): 最も遠いデータ間の距離を基準とする。クラスター内の一貫性を重視し、異なる特性を持つグループを明確に分離したい場合に適している。
・重心法: 各クラスターの重心(平均値)間の距離を基準とする。
最大のメリットは、事前にクラスター数を決める必要がない点です。デンドログラムを任意の高さでスライスすることで、分析結果を見ながら適切な分割数を判断できる柔軟性を持っています。
一方、デメリットとしては、サンプル数が増えると計算量も増大し、処理が困難になる点が挙げられます。また、データ量が多いとデンドログラムが複雑になりすぎてしまい、視覚的な解釈が難しいという側面もあります。
非階層クラスター分析(Non-hierarchical Clustering)
非階層クラスター分析は、あらかじめ設定したクラスター数に基づき、全サンプルを一括してグルーピングする手法です。
階層型とは異なりデンドログラムは作成されませんが、各データがどのグループに属するかをリストや散布図によって明確に特定できます。最大のメリットは計算負荷が低いことで、ビッグデータなどの大規模なサンプルを分析・考察する際に有効です。
一方で、「クラスター数(k)」は事前に人間が指定しなければなりません。この設定次第で結果や考察が大きく変わるため、最適な分類数を見極めるための試行錯誤が必要となります。
代表的な手法:k-means法
k-means法は非階層クラスター分析の代表格であり、以下の手順で計算が行われます。
1. 初期値の設定:ランダムにk個の核(中心点)を選ぶ。
2. 割り当て:各データを最も近い核のクラスターに割り当てる。
3. 核の更新:割り当てられたグループの重心を計算し、新たな核とする。
4. 収束:重心が移動しなくなるまで、2と3のプロセスを繰り返す。
その他の手法:超体積法(V-method)
超体積法は、データの「密度」に着目した手法です。 データの分布密度が高い領域をクラスターとして認識するため、k-means法とは異なり、事前にクラスター数を指定する必要がない場合もあります。 データの塊をそのまま捉える性質があるため、複雑な形状のクラスターも抽出できるのが特徴です。
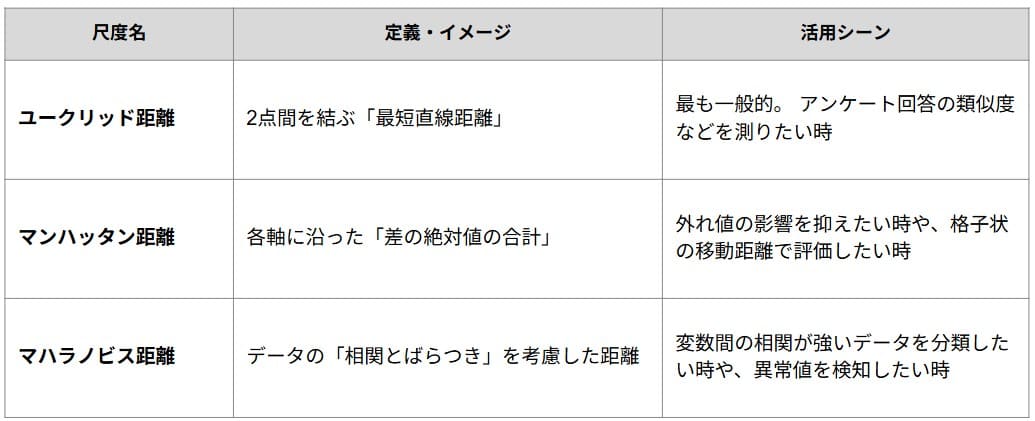
類似度を測る距離尺度
クラスター分析では、データ同士がどれほど似ているかを「距離」として数値化します。距離が短いほど類似度が高いと判断されますが、データの性質によって最適な計算方法が異なります。代表的な距離尺度は以下の通りです。
クラスター分析の実施手順
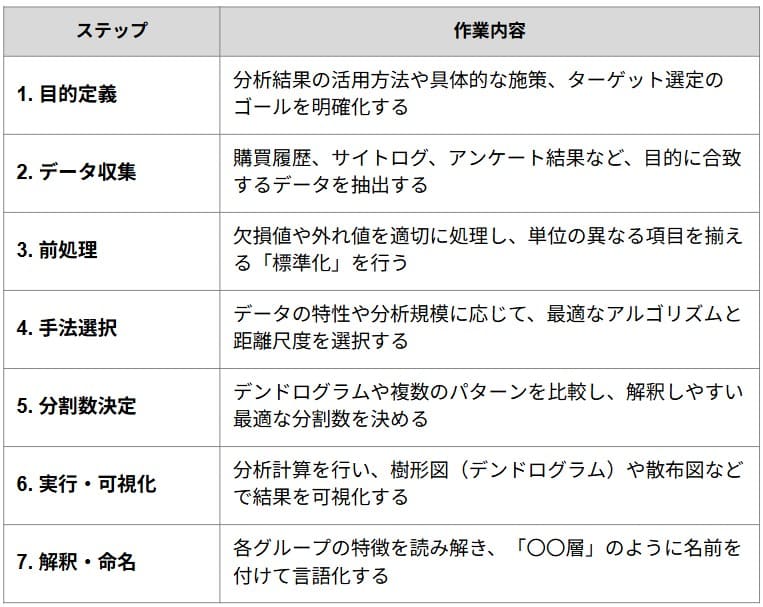
クラスター分析において、ツールを用いた計算はあくまでプロセスの一部です。分析の成功は、事前のデータ整理と、事後の「結果に対する解釈」にかかっています。
具体的にどのような流れで進めるべきか、基本の7ステップを順に見ていきましょう。
クラスター分析の進め方:7つのステップ
ビジネス・マーケティングでの具体的な活用事例
クラスター分析が実際にどのような現場で役立っているのか、5つの活用事例で紹介します。
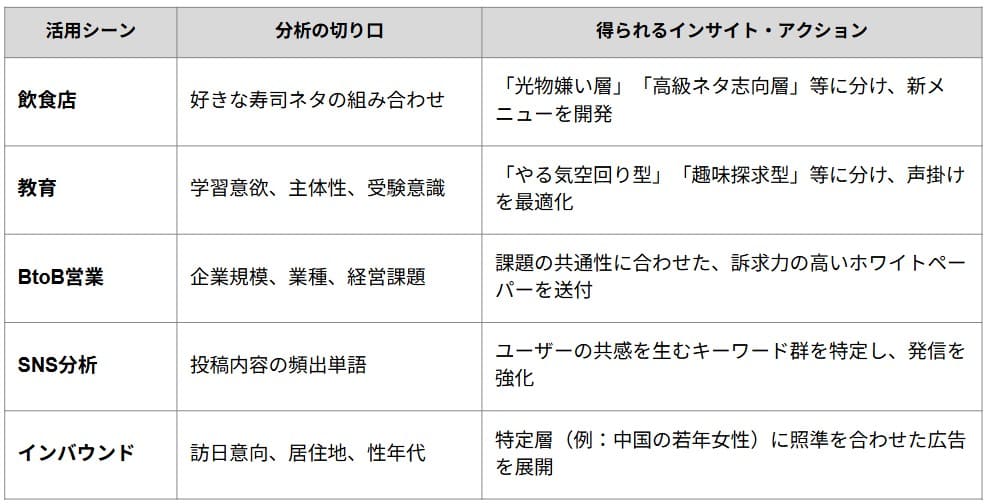
事例1:寿司ネタの選好による顧客分類

アンケートで収集した「好きな寿司ネタ」の多変数データに対し、二段階のクラスタリングで構造を可視化した事例です。
分析プロセス
1. 階層型でネタ同士の親和性を分類(例:大トロと中トロを「高級ネタ」に集約)
2. 整理されたネタのグループに基づき、非階層型で回答者をタイプ別に分類
抽出結果(例)
・高級志向層:大トロ、中トロ、ウニなどを好む層
・定番志向層:赤身、白身、光物などを中心に好む層
これにより、クラスター分析を通じて各グループの構成比を把握し、ターゲットに合わせたメニュー開発やプロモーションが可能になります。
事例2:教育現場における生徒の学習タイプ分類

生徒の性格や学習意欲に関するアンケートデータを活用し、個々の特性に応じた指導方針を策定した事例です。
分析プロセス
1. 階層型で「主体性」「受験意識」などの変数をグループ化し、評価軸を整理
2. 整理された評価軸に基づき、非階層型で全生徒を4つのタイプに分類
抽出結果(例)
・タイプ1: 受験意欲も主体性も高い「やる気満々層」
・タイプ2: 真面目だが空回りしがちな層
・タイプ3: 勉強も受験も楽しくない「無関心層」
・タイプ4: 受験には興味ないが、勉強自体を楽しんでいる「趣味・探求層」
この分類に基づき、タイプ別の声かけや指導方法の最適化を図ります。
事例3:BtoBマーケティングでのターゲティング

見込み顧客を「企業属性」と「経営課題」の多変数で分類し、アプローチを最適化した事例です。
分析プロセス
1. 階層型で多岐にわたる経営課題を数グループ(例:「守りの効率化」「攻めの開拓」)に集約
2. 抽出された課題軸に基づき、非階層型で見込み顧客をタイプ別に分類
抽出結果(例)
・コスト最適化層:業務効率化や経費削減を最優先課題とするグループ
・市場開拓志向層:新規事業や売上拡大のソリューションを求めているグループ
各層の関心事に即したホワイトペーパー送付やウェビナー案内を行い、商談化率を向上させます。
事例4:SNSアカウントの共感分析

人気SNSアカウントの過去投稿を、テキストマイニングとクラスター分析を組み合わせて解析した事例です。
分析プロセス
1. テキストマイニングで投稿内の頻出語を抽出
2. 階層型で単語同士の共起性(同時に使われる傾向)を分析し、投稿テーマを分類
抽出結果(例)
・親密クラスター:「感謝」「お祝い」「日常」などの単語群
・情報クラスター:「解決」「コツ」「裏技」などの単語群
エンゲージメントに直結するキーワードを特定し、共感を得やすい発信スタイルの指針を策定します。
なお、テキストマイニングについては下記のページでも解説しています。
事例5:インバウンド市場のターゲット戦略

訪日外国人旅行者の意識調査をクラスター分析し、5つの主要セグメントを特定した事例です。
分析プロセス
1. 階層型で「訪日動機」や「旅行への期待」などの心理的変数を集約
2. 特定された価値軸に基づき、非階層型で旅行者を5つのクラスターに分類
抽出結果(例)
・訪日高意欲層:具体的な旅行計画があり、リピート意向も強いグループ
・日本文化体験層:ショッピングよりも伝統文化や体験を重視するグループ
高意欲層に多い属性(例:中国の若年女性)を特定し、ピンポイントな広告配信で投資対効果の最大化を図ります。
クラスター分析を支える主要ツールとプログラミング言語
クラスター分析には膨大な計算が必要なため、Excelのアドインよりも専用のソフトや言語を使うのが一般的です。
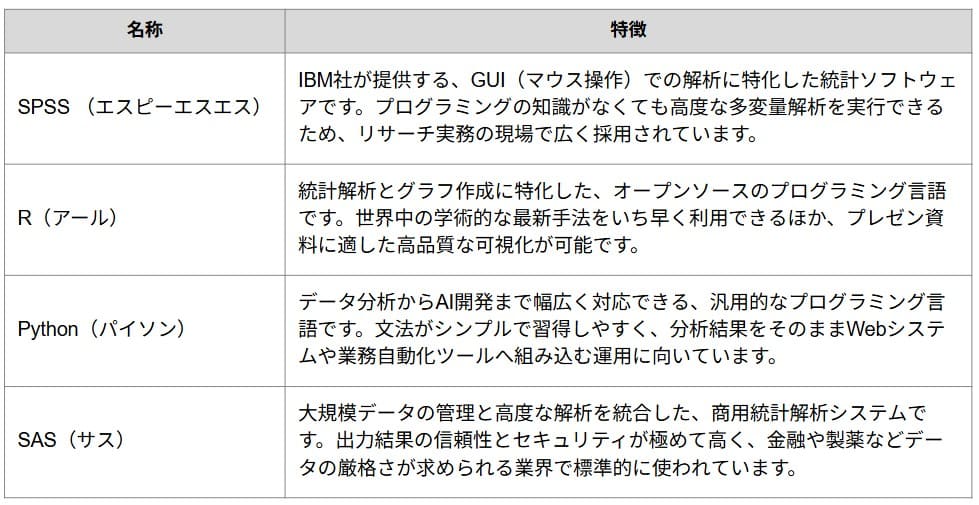
クラスター分析成功のための応用テクニック

ここでは、クラスター分析を成功に導く応用テクニックについてご紹介します。
因子分析との組み合わせ
クラスター分析の実務では、まず因子分析でデータの次元を圧縮し、算出された「因子得点」を用いてクラスタリングを行う手法が一般的です。
アンケートの質問項目が多すぎる場合、そのまま分析するとノイズの影響で分類精度が低下します。因子分析で背後の共通要素を抽出してから分類することで、より解釈しやすく安定したクラスターを得られます。
フェイスシートとのクロス集計
クラスター分析で得られた分類結果に対し、年代・職種・年収などの属性情報(フェイスシート)を掛け合わせてクロス集計を行います。
クラスターに具体的な属性データを紐付けることで、そのグループが「どのような人々か」というペルソナ像を肉付けし、実効性の高いマーケティング戦略へと繋げます。
クロス集計については下記の記事でも解説しているため、あわせてチェックしてみてください。
クラスター分析の注意点
分析の精度を高め、誤った意思決定を防ぐために把握しておくべき3つの注意点を解説します。
・解釈の客観性保持
クラスター分析はあくまで「分類」を行う手法であり、各グループにどのような意味を持たせるかの最終判断は人間に委ねられます。偏った思い込みを避けるため、分析結果は複数人で客観的に検討することが重要です。
・因果関係の非明示
クラスター分析はデータの類似性を示すものであり、「なぜそのグループになったのか」という因果関係までは証明しません。背景にある要因を特定したい場合は、必要に応じて回帰分析など他の統計手法と組み合わせる必要があります。
・外れ値による歪み
特殊なデータ(異常値)が一つ含まれるだけで、クラスター構造全体が大きく歪んでしまう特性があります。分析の精度を担保するためには、事前のデータクレンジング(外れ値の除去や補正)が重要です。
クラスター分析ならロイヤリティ マーケティングへ
クラスター分析は、複雑で混沌としたデータの世界に「秩序」をもたらす手法です。
セグメンテーションによる各顧客への最適なアプローチを実現するだけでなく、データに潜む市場の隙間やインサイトの発見、さらには可視化を通じたチーム全体でのターゲット像共有を可能にします。
ただし、大規模データの処理や結果の妥当な解釈には高度な専門性が求められ、実務上の壁となるケースも少なくありません。自社内でのリソース確保が困難な場合は、外部の専門家を活用することも極めて有効な選択肢です。
弊社には膨大なデータを熟知したアナリストが在籍しており、課題の抽出から具体的な分析まで一貫して伴走いたします。データに基づく意思決定でビジネスの成長を加速させたい方は、ぜひ一度お問い合わせください。
最新の自主調査やお役立ち情報をお届けするメルマガを配信!登録はこちら



お気軽にお問い合わせください
詳しくお知りになりたい方はお問い合わせ