
コラム
![]() 2025-08-25
2025-08-25
生成AIで読み解く“自由記述”― ChatGPTで始める定性データ分析の第一歩―

■本記事の概要
・ ChatGPTの標準機能のみを使い、社内アンケート(架空)の自由記述200件を対象に、無意味な回答の除外から感情分析、話題の分類、部署ごとの傾向整理まで一通りの分析を実施。
・ 自由記述形式であっても、ChatGPTとの対話を通じて回答傾向や構造を抽出できる可能性が示唆され、生成AIの実務活用余地を確認。
・ 今後はAPIやPythonを用いることで、より深い洞察や定量評価が可能となり、実務での活用範囲が広がると考えられる。
目次
はじめに
生成AIの進化が目覚ましい今、その力を活かして「テキスト分析」はどこまで出来るのでしょうか。
企業には、アンケートの自由記述やお問い合わせ内容、商談メモなど、言葉のデータが数多く眠っていると思います。
ただ、分析環境の整備には時間と手間がかかり、結局手つかずになっていることも多いのではないでしょうか。
「生の声」の中にはまだ気づかれていない発見が眠っているはずで、今回はChatGPTを使ってどこまでテキスト分析が可能かを検証してみました。
前提条件
今回の検証では、ChatGPT Plus(GPT-4oモデル)の利用を想定しています。
なお、現在は無料版との機能差もそこまで大きくないため、同様の分析は無料版でも十分再現可能と考えられます。
拡張機能(ファイルの直接投入やコードインタプリタ)は使用せず、標準的な対話のみで分析を行いました。
使用したデータは、架空の「社内の働きやすさに関するアンケート(200件)」です。
具体的には以下のような構成です:
―ID:連番で付与された識別子
―部署:回答者の所属部署
―自由記述:働きやすさについての意見や感じていること
このシンプルなテキストデータをもとに、ChatGPTだけでどこまで分析や洞察が可能かを検証していきます。
流れとゴール
本検証のゴールは、テキスト分析を通じて部署ごとの傾向や共通の課題を把握できる状態にすることです。
ChatGPTを活用し、以下のステップで分析を進めていきます
1. データ読込みと条件設定
データの読み込みと生成AIに振る舞いを設定
2. 無回答や意味のない記述の除外
分析対象を絞り、結果の信頼性を確保する
3. 個人名などの固有情報のマスキング
プライバシーに配慮しつつ、内容の一般化を行う
4. 記述内容の分類・感情分析(ネガポジ判定)
「何に対して肯定的か/否定的か」を明らかにする
5. タグ付けやクラスタリングによるグルーピング
類似した意見をまとめ、主な話題の流れを整理する
6. 部署別のクロス集計による可視化
部署ごとに見られる傾向や共通点の違いを把握する
この一連の流れを通じて、「誰が何に困っているのか/どのような改善点が見えてくるのか」を捉えられるのかを検証していきます。
1.データ読込みと条件設定
ChatGPTでの分析精度を高めるために、まずは「ペルソナ設定(役割の指定)」を行います。
今回使用したプロンプトは以下の通りです。
プロンプト
あなたは、統計解析とビジネス活用の両方に精通したデータサイエンティストです。
自然言語処理領域に強く、アンケートデータを活用した分析が得意です。
分析の目的やデータの構造に応じて、適切な手法・視点を自ら選び、読み手が理解しやすい形で結果を要約・可視化・言語化することが出来ます。
続いて、分析対象となるデータの読み込みです。
今回は約200件のアンケート回答を、そのままプロンプト内に貼り付けて処理しました。
行数が極端に多くなければ、ChatGPTでも十分対応可能です。
あわせて、データ構造や分析の流れ、ゴールも併せて指示しています。

2.無回答や意味のない記述の除外
分析の最初のステップは、「使えない回答」を取り除くことです。
「特になし」「?」「うーん」などの無内容な回答や、単語数が極端に少ないもの、テンプレ的な表現などは除外対象とします。
こうしたノイズが残ったままだと、分析結果に偏りが出る可能性があります。
生成AIを使えば、曖昧で判断しづらい回答もある程度自動で見分けることが可能です。
使用したプロンプト

出力結果
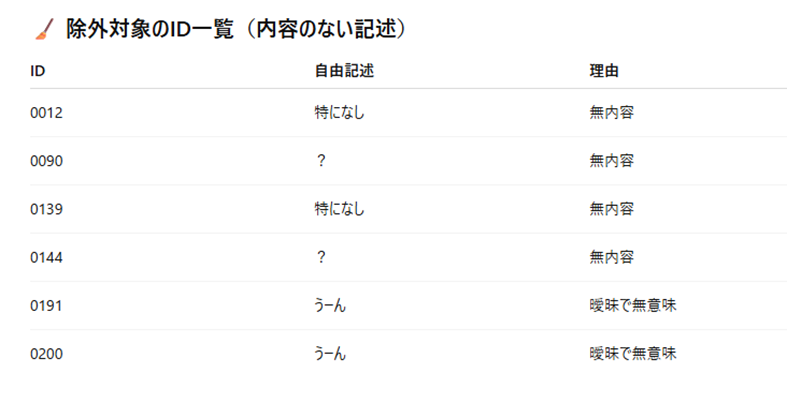
「特になし」などの無内容な回答を除外した結果、分析対象は194件となりました。
この前処理済みのデータをもとに、以降の分析を進めていきます。
3.個人名などの固有情報をマスキング
自由記述の中には、「○○さんが言っていた」「△△部長が対応してくれた」など、特定の個人や部署名が含まれていることがあります。
そのまま分析や共有に使うと、意見の内容ではなく誰が書いたか・誰について書かれたかが注目されてしまい、分析の目的からずれる可能性があります。
社内での気まずさや関係悪化を防ぐためにも、特定の個人が特定されないようにマスキングを行います。
(※ただし、クローズドな分析や、人物視点が重要な場面では、あえてマスキングしない判断も有効です。)
目的や共有範囲に応じて、適切に判断して対応します。
使用したプロンプト

出力結果

このように、たとえば先ほどまで「田中さん」と具体的な名前で記載されていた内容は、自動的にマスキングされ、
個人が特定されない表現へと置き換えられました。
4.記述内容の分類・感情分析(ネガポジ判定)
自由記述のアンケートには、「よかった」「不満」「改善してほしい」など、さまざまな感情が含まれています。
こうした感情の傾向を把握することで、単に話題が何かだけでなく、どう感じているかを読み取ることができます。
同じ「評価制度」についての意見でも、「評価が明確で納得感がある」→ ポジティブ
「何を基準に評価されているのか分からない」→ ネガティブ
このように内容×感情の掛け合わせで見ることで、改善すべき領域やうまくいっている点を整理しやすくなります。
また、部署ごとや時期ごとの感情の変化を比較することで、モチベーション低下の兆しなど、定量データでは見えにくい変化にも気づける可能性があります。
プロンプト

出力結果(ポジティブ意見)

出力結果(ネガティブ意見)

分かること
全体的にポジティブな意見はやや少なめではあるものの、「チームの雰囲気が良い」など前向きな声も一定数見られる。
一方で、ネガティブな意見のほうが圧倒的に多く、とくに評価制度や人事に対する不満が目立つ傾向にある。
5.タグ付けやクラスタリングによるグルーピング
自由記述は一つひとつの意見がバラバラに書かれているため、そのままでは全体像をつかむのが難しく、傾向も見えにくくなります。
そこで有効なのが、内容ごとにタグを付けたり、似た内容をグループにまとめる(クラスタリング)という作業です。
たとえば:
「会議が多すぎて業務が進まない」
「毎日会議で、集中する時間がない」
→ 両方とも「会議の多さ」という1つの話題に分類できます。
このように、似た意見を話題ごとにまとめることで、どのテーマに意見が集中しているかがわかり、分析が格段にしやすくなります。
プロンプト

出力結果
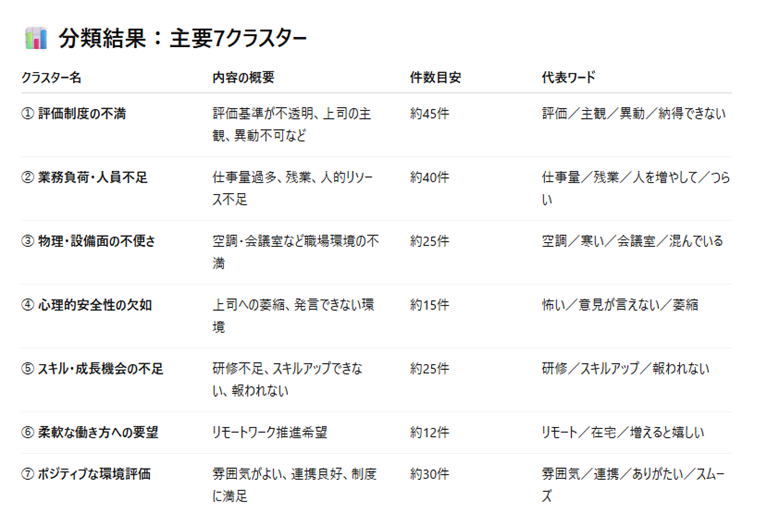
わかること
分類結果からは、制度や業務体制といった構造的な課題に不満が集まっていることが見えてきました。
これらを的確に改善できれば、幅広い社員の満足度を押し上げる可能性があると言えます。
6.部署別のクロス集計による可視化
自由記述の意見を整理して終わりにするのではなく、「誰がどんなことを感じているか」まで掘り下げることで、具体的な改善に活かすことができます。
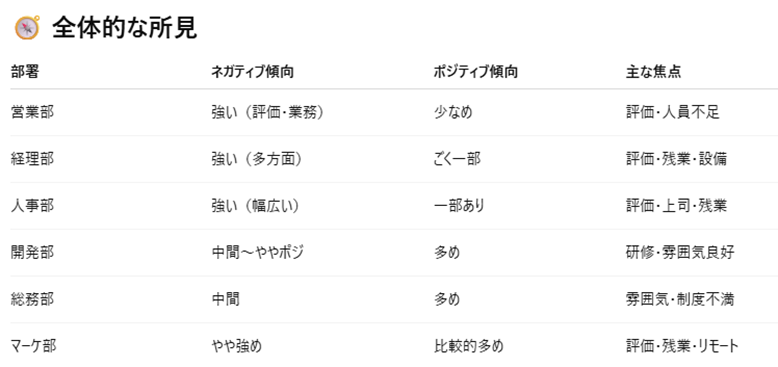
特に、ネガポジや話題のタグを部署ごとに集計・可視化すると、次のような示唆が得られます:
「営業部では“業務量の不満”が目立つが、開発部では“評価制度”への声が多い」
「総務部は全体的にポジティブな意見が多く、職場環境に満足している」
このように、部署ごとの傾向や課題の違いを“見える化”することで、対応すべき優先順位が明確になります。
プロンプト

出力結果
出力結果(考察と提言)

最後に
今回は、社内の働きやすさに関する200件の架空データをChatGPTに読み込ませて分析してみましたが、標準機能だけでも意外としっかり傾向が見えることが分かりました。
今後はコードインタプリタなどの機能を組み合わせることで、さらに深い分析や可視化も期待できそうです。
ここまでお読みいただき、ありがとうございました!
最新の自主調査やお役立ち情報をお届けするメルマガを配信!登録はこちら



お気軽にお問い合わせください
詳しくお知りになりたい方はお問い合わせ