
コラム
![]() 2026-02-26
2026-02-26
構造化データとは?非構造化データとの違いや目的、ビジネスでの活用方法を解説

構造化データとは、検索エンジンへの情報伝達やビジネス分析において重要な役割を果たすデータ形式です。本記事では、非構造化データとの違いや具体的な導入メリット、活用法までをわかりやすく解説します。データを武器に成果を出したい担当者の方は、ぜひ最後までご覧ください。
目次
構造化データとは
構造化データをビジネスで有効活用するためには、まずその基本的な意味や種類、構築方法を正しく理解する必要があります。どのようなデータが該当するのか整理しておけば、検索対策やデータ分析への応用もスムーズになるでしょう。
構造化データの定義

構造化データとは、あらかじめ決められた規則に従って整理され、標準化された形式を持つデータのことです。一般的には行と列の概念を持つ表形式で構成されており、コンピューターと人間の双方が内容を理解しやすいという特徴があります。
データの属性が明確に定義されているため、情報の検索や集計といった処理を効率的に行える点が大きなメリットです。その名の通り「構造化」されていることから、ツールやアルゴリズムによる解析にもっとも適したデータ形式といえます。
ビジネスで扱われる構造化データの種類
ビジネスの現場では、活用の目的に応じてさまざまな種類の構造化データが利用されています。もっとも身近な例としてはExcelやCSVファイルが挙げられますが、それ以外にも企業のシステム内で管理されている多くの情報が該当します。
ビジネスで利用される構造化データの主な例
・業務で日常的に作成するExcelやCSVファイル
・顧客管理システム(CRM)に登録された顧客リスト
・店舗のPOSレジで記録される売上データ
・在庫管理システムで管理される商品の入出庫ログ
・Webサイトのお問い合わせフォームから送信された回答
これらのデータは、あらかじめ決められた形式で整理されるため、集計や分析を効率的に進められます。日々の業務で扱う情報の多くが、実は構造化データとして蓄積されているのです。
非構造化データとは
次に、構造化データの対照となる「非構造化データ」について解説します。ビジネスの現場にあふれるこのデータの特徴と具体例を把握することで、データ活用の全体像がより明確になります。
非構造化データの定義

非構造化データとは、あらかじめ決められた形式や規則を持たないデータのことを指します。構造化データのように行と列で整理されておらず、そのままでは従来のデータベースに取り込んで管理したり集計したりすることが難しいのが特徴です。
内容や構成が不規則であるため、コンピューターによる直接的な解析には不向きな一方、ビジネスの現場で生成される情報の大部分は非構造化データが占めているのが現状です。
非構造化データの具体例
ビジネスの現場には、行と列の表形式には収まりきらない多種多様なデータが存在します。人間が日常的に使う言葉や視覚的な情報などが該当し、その種類は多岐にわたります。
ビジネスで発生する主な非構造化データの例
・日常業務で送受信されるメールやチャットの履歴
・WordやPDF形式で作成された企画書や議事録
・Webサイトやカタログで使用する商品画像や動画ファイル
・コールセンターで録音された顧客との通話音声
・SNS上の口コミやコメントなどの定性的な情報
たとえば、メールの本文やSNSの投稿内容は顧客の本音やニーズを探るための極めて貴重な情報源ですが、売上高のような数値データと同じ手法で単純計算することはできません。
また、データの形式が多岐にわたり、従来の方法では整理や検索が難しいため、活用するには専用の保存場所や高度な分析ツールを必要とする点も特徴です。
構造化データと非構造化データの違い
データ活用を成功させるためには、構造化データと非構造化データの違いを把握しておく必要があります。形式のルールや保存環境、そして分析のしやすさといった観点から、特徴を比較して理解を深めていきましょう。
データ形式の規則性

構造化データと非構造化データの決定的な違いは、フォーマットにあらかじめ定義された規則性の有無です。
構造化データは事前に決められたデータモデルに従って整理されており、枠組みが明確なためシステムでの処理や集計に適しているのが特徴です。一方で、非構造化データはメールの文章や画像、音声のように特定の定義を持たず、形式もサイズも多岐にわたります。
データの保存方法
構造化データと非構造化データでは、それぞれ適した保存場所や管理システムが異なります。Webシステムなどで効率的にデータを運用するための主な構築・保存方法は以下の通りです。
データ保存方法と環境の比較
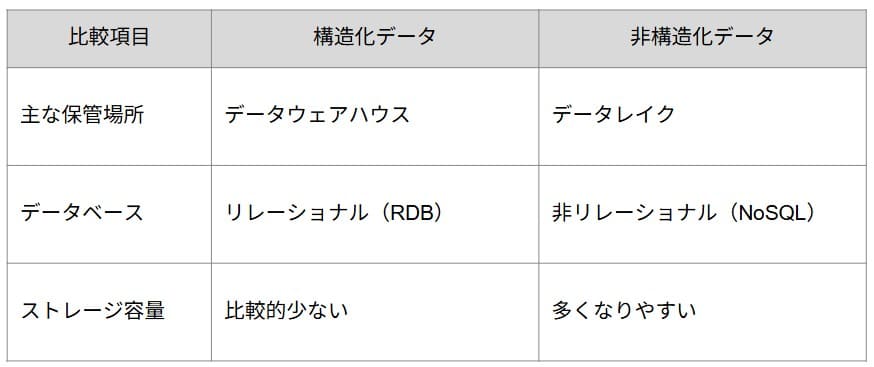
構造化データは、整理された状態でデータウェアハウスやリレーショナルデータベースに格納されるのが一般的です。一方、非構造化データは、未加工のままデータレイクへ保存されたり、NoSQLなどの柔軟なデータベースで管理されたりするケースが多く見られます。
保存に必要な容量にも差があるため、扱うデータの種類に合わせた環境選びが大切です。
データ分析の難易度

構造化データと非構造化データでは、分析にかかる手間や難易度が大きく異なります。
構造化データは検索や集計に適した形式になっているため、既存の分析ツールやアルゴリズムを用いて迅速に結果を導き出せるのが大きなメリットです。一方で非構造化データは、分析可能な形式へ変換するための高度な前処理を必要とします。
活用には自然言語処理やAI技術の導入が不可欠であり、専門的な知識やスキルが求められるため、扱うためのハードルは必然的に高くなります。
構造化データを活用する目的
構造化データを活用する主な目的は、SEO対策やビジネスにおける意思決定の支援です。それぞれの役割を正しく理解し、自社の課題解決にどう役立てるべきか、具体的なイメージをつかみましょう。
検索エンジンに情報を正しく伝える

構造化データを活用する主要な目的は、検索エンジンに対してWebサイト上のHTMLページの内容を正確に伝えることです。JSON-LDなどの形式で適切にマークアップを行うことで、検索エンジン(クローラー)がページ内の情報をより的確に認識できるようになります。
Webページの内容をクローラーがスムーズに解釈できれば、インデックス登録の迅速化が期待できるだけでなく、検索結果に詳細情報を付加する「リッチリザルト」の表示にもつながります。
つまり、構造化データの実装は、サイトの情報をクローラーに正しく認識させ、Webサイトの露出を最適化するために有効なSEO施策といえます。
ビジネスの意思決定を支援する

構造化データは、ビジネスにおける意思決定の精度を高めるためにも活用されます。数値や項目があらかじめ定義された構造化データは、現状を客観的な事実として素早く把握するのに適した形式です。
ビジネスの現場において、勘や経験則のみに依存した判断は方向性のブレを招く可能性がありますが、整理されたデータを根拠にすることで、主観を排除した論理的な結論を導き出せるようになります。
分析時のミスや手間を減らし、生産性の高い戦略立案を行ううえで、構造化データの存在は大きな支えとなるでしょう。
データ処理の自動化と効率化を図る

構造化データを活用するもう1つの重要な目的は、データ処理の自動化によって業務全体の効率化を図ることです。データの形式や属性がバラバラな状態では、システムに取り込む前に人間が修正作業をする手間が生じます。
その点、構造化データはあらかじめ機械が読み取りやすい規則に従って記述されているため、RPAやAIなどのツールと親和性が高く、エラーの少ないスムーズな自動処理を実現できるのが特徴です。
データの整形に費やしていた時間を削減し、より付加価値の高い業務にリソースを割くことが可能になります。
構造化データを導入するメリット
構造化データの適切な導入は、Webサイトの集客力向上や業務効率化など、ビジネスに大きな恩恵をもたらします。ここでは、具体的にどのような効果が期待できるのか、代表的な3つのメリットについて詳しく解説します。
リッチリザルトによる流入が増加する

WebサイトのHTMLに構造化データを実装することで、検索結果にリッチリザルトが表示される可能性が高まります。リッチリザルトとは、通常のテキスト情報に加えて、商品画像やレビューの星評価、価格などを視覚的に強調して表示する機能のことです。
検索ユーザーの目に留まりやすくなるため、通常の表示と比べてクリック率の大幅な向上が期待できます。ページを訪問する前に主要な情報が伝わることで、購買意欲の高いユーザーを効率的にサイトへ誘導できる点は大きなメリットです。
データの集計や管理が効率的になる

構造化データを導入することで、データの集計や分析における「情報の取り出しやすさ」が格段に向上します。あらかじめデータの型が決まっているため、専門的なプログラミング技術がなくても、表計算ソフトや分析ツールを用いて容易に可視化できます。
広く普及している形式であるため、既存の多くのツールとスムーズに連携でき、導入後すぐに現状の把握や数値の比較を行えるのが強みです。
また、機械学習などの高度な解析に移行する際も、複雑なデータ整形が不要なため、分析から戦略立案までの時間を大幅に短縮できます。
システム間の相互運用性を高める
構造化データの導入は、異なるシステム間でのスムーズなデータ連携を可能にします。
標準的なルールに基づいて構築された構造化データは、特定のツールやソフトウェアに依存しない「共通言語」としての役割を果たすため、システム刷新や新しい外部サービスとの接続が容易になります。
たとえば、既存のデータベースから最新のクラウドサービスへ情報を移行する際も、形式が整っていれば複雑な変換処理を介さず、データの整合性を保ったまま移し替えることができます。
構造化データの課題
構造化データの導入には多くのメリットがありますが、運用にあたってはいくつかの課題も存在します。活用時の制約やリスクについて事前に把握しておきましょう。
意図した目的以外での活用が難しい

構造化データは、特定の用途に合わせて整理されているため、当初の想定を超えた活用が難しいという側面があります。
たとえば、予約管理のために作られたデータを使ってマーケティングの効果測定を行おうとしても、必要な項目が含まれていなければ分析できません。新しい視点で分析を行いたい場合は、データの構造自体を見直したり、別の情報を追加して紐づけたりする工数が発生します。
特定の範囲内では極めて強力ですが、未知の課題や想定外のニーズに対して即座に応用しにくい点は、構造化データ特有の制約といえるでしょう。
要件変更に大きなコストがかかる

構造化データを利用する環境では、運用開始前にデータの定義である「スキーマ」を厳密に決定しておく必要があります。この設計段階でのルールが運用の土台となるため、後から変更を加えることは容易ではありません。
ビジネス環境の激しい変化に伴い、新しい分析軸を追加しようとしても、既存システムとの整合性を保ちながら構造を修正するには多額の費用や人的リソースを要します。
整理整頓されているがゆえに、急な仕様変更や要件の追加に対しては、対応コストが膨らみやすいという特徴を持っている点に注意が必要です。
構造化データの活用や分析の相談ならロイヤリティ マーケティングへ
構造化データや非構造化データを適切に管理・分析することは、企業の意思決定やマーケティング成果を最大化するために欠かせません。しかし、膨大なデータを自社だけで収集し、高度な分析環境を構築するには多くのリソースが必要です。
ロイヤリティ マーケティングでは、1億人超のPonta会員基盤から得られる属性データや実利用データを活用し、貴社のマーケティングを強力に支援します。
「Ponta DMP」を用いた多面的な顧客分析や、購買・行動データに基づくリサーチにより、データドリブンな意思決定と施策実行をサポートいたします。ぜひお気軽にお問い合わせください。
.jpg)


お気軽にお問い合わせください
詳しくお知りになりたい方はお問い合わせ