
コラム
![]() 2024-11-21
2024-11-21
拡大推計とは?やり方やコツ、活用方法を知ってデータを分析してみよう

拡大推計は、身近なマーケティング手法の1つですが、具体的にどのようなものかご存知でしょうか。実は現在、機械学習やビッグデータとともに使われており、活用場面が広がっています。本記事で拡大推計のやり方やコツ、活用方法を押さえ、データ分析に活用してみましょう。
目次
拡大推計とは
拡大推計とは、限られたサンプルデータから全体の傾向を推測する統計手法のことを指します。サンプルとは、母集団の中から抽出した集まりのことで、拡大推計やアンケートの話題でよく使われる言葉です。
一見難しそうなやり方ですが、実は拡大推計と同じようなことを私たちは日常生活で行なっています。例えば、買い物の際に陳列商品の一部を見て店舗全体の商品の品質を判断する行為や、調理の際に味見をして料理全体の味を判断する行為です。
つまり、少数のサンプルから得た結果を大きな母集団に当てはめることで、全てを調べずに効率よくデータを得られるのが拡大推計だといえます。拡大推計をマーケティングで活用すると、限られたリソースで効果的に戦略を立案したり、市場の傾向を把握したりといったことが可能です。
拡大推計のやり方
拡大推計にはさまざまなやり方がありますが、ここでは一般的なやり方としてウェイトバック集計について解説します。
ウェイトバック集計とは

ウェイトバック集計は、サンプルデータの偏りを補正し、拡大推計の結果をより正確なものへと導く集計方法のことです。「ウェイト」は重みのことで、アンケートの各回答に重みをつけて調整し、サンプルの構成比を母集団の構成比に近づけます。
では、なぜ回答に重みをつけて調整する必要があるのでしょうか。それは、アンケート回答の構成比と母集団の構成比に差がある場合、ズレを修正することで拡大推計の精度を高められるからです。
例えば、男性と女性が1:1の割合でいる地区Aでアンケートを実施するとしましょう。下記のように回答者の男女比が母集団の男女比と変わり、男性の回答率が女性より低くなると、男性の意見が反映されていない拡大推計となってしまいます。
A地区で実施したアンケート結果
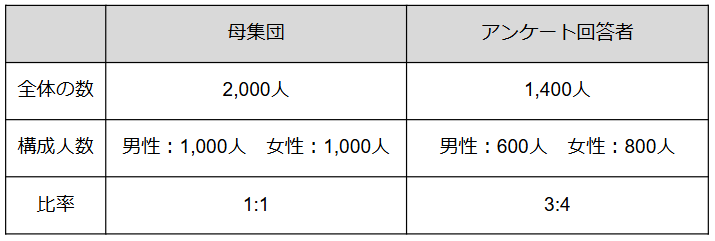
そこで、回答者に重みをつけ、本来の母集団の構成比に近づけるのがウェイトバック集計です。下記のように男性の回答者に重みをつけるとデータが実態に近づき、より正確な拡大推計につながります。
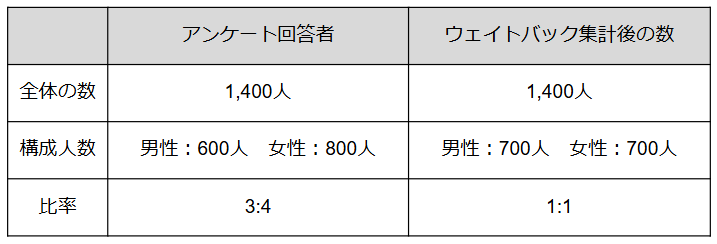
ウェイトバック集計のやり方

ウェイトバック集計を正しいやり方で実施すると、拡大推計の精度が高まります。下記のアンケート結果の例を使い、ウェイトバック集計の流れや計算方法をチェックしてみましょう。
A地区で実施したアンケート結果
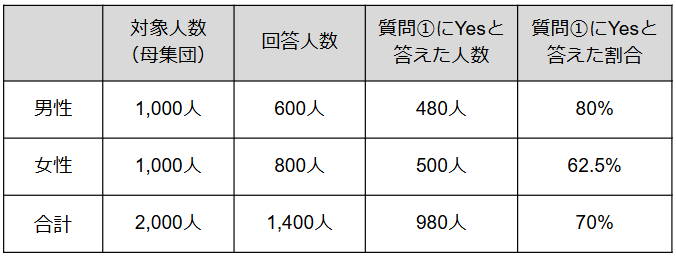
①補正内容を決める
アンケートを実施したら、まずはどの属性にどのような補正を行うのかについて決定します。一般的には、性別、年齢、地域などの基本的な属性が用いられます。属性について、サンプルの構成比と実際の母集団の構成比を比較し、大きな差がある部分を特定しましょう。
例えば、アンケートに回答した男女比と実際の母集団の男女比が異なる場合、母集団に合わせて性別の割合の補正が必要だと判断できます。また、調査の規模や内容によっては、「日本の人口と同様の比率にする」といった補正の仕方も可能です。
地域Aで実施したアンケート結果の例で考えると、回答した男女比が3:4で、実際の母集団の男女比が1:1のため、1:1になるように男性700人、女性700人といったように補正します。
A地区でのアンケート結果に関する補正内容
・【実際の母集団】男性:女性=1,000人:1,000人=1:1
・【回答者】男性:女性=600人:800人=3:4
・【補正】男性:女性=700人:700人=1:1
②ウェイトバック値を求める
次に、各属性カテゴリのウェイトバック値を計算しましょう。ウェイトバック値とは、どのくらいの重みをつけるのかを示す値のことで、事前に決めた補正後の値を補正前の値で割ると求められます。
A地区の例で考えると、回答者の男性は補正前に600人、補正後は700人となるため、男性のウェイトバック値は700÷600=1.166…です。女性のウェイトバック値も男性と同様に計算します。
A地区のアンケート結果に関するウェイトバック値
・男性:700÷600=約1.166(小数点第3位以降 四捨五入)
・女性:700÷800=0.875
③調査結果を補正する
最後に、算出したウェイトバック値を用いて、調査結果を補正します。アンケート結果の補正したい値にウェイトバック値を掛け合わせて、母集団の構成比に近い数値にしましょう。
例えばA地区のアンケート結果で計算する場合、「質問①にYesと答えた人数」が補正したい値です。男性の該当人数は480人のため、480×1.166=559.68となります。同様の方法で女性の値も計算できます。
「質問①にYesと答えた人数」のウェイトバック集計
・男性:480×1.166=559.68
・女性:500×0.875=437.5
以下は、結果をまとめたものです。
A地区のアンケート結果のウェイトバック集計
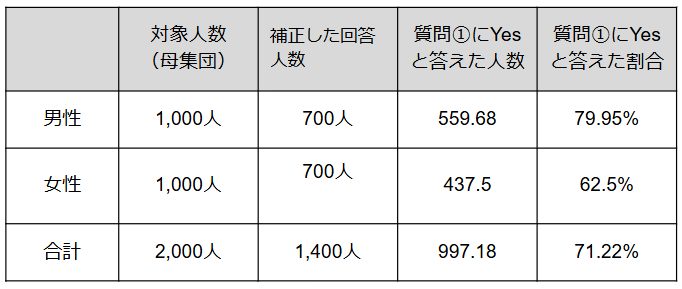
集計前の「質問①にYesと答えた割合」の全体の数値は70%であったため、集計後の71.22%と比べると1.22%実情に近い数値となりました。また、女性の「質問①にYesと答えた割合」は補正前後で同じであり、人数の比率を変えずに補正がかけられたことになります。
このように、ウェイトバック集計を行うとサンプルの偏りが修正され、より実態に近い拡大推計が実現可能です。
ウェイトバック集計の注意点

ウェイトバック集計は有用な手法ですが、適切に使用しないと誤った結果を招く可能性があります。以下の3点に注意し、より信頼性の高い拡大推計を実施しましょう。
定性調査では実施しない
ウェイトバック集計は、主に定量調査で用いられる手法であり、数値化できない情報を収集する定性調査には適していません。
そもそも定性調査とは、言葉や感情など数値化できない質的な情報を集めて調査する手法のことです。これに対して、数値で表せるデータを調べる手法を定量調査といい、マーケティングリサーチに含まれる多くの手法は定量調査と定性調査のどちらかに分類できます。
ウェイトバック集計は人数や割合といった量的データの活用に適しており、行動の理由や意見などの質的データの分析には不向きです。
人数が少ない調査での活用は避ける
ウェイトバック集計は、ある程度の規模のサンプルを持つ調査に適しており、人数が少ない調査には向いていません。サンプル数が少ない状態でウェイトバック集計を行うと、1人の回答に対するウェイトの影響が大きくなりすぎて、拡大推計の精度が低くなる恐れがあります。
ウェイトバック値を3以上にしない
ウェイトバック値は最大でも2程度が望ましく、3以上になる場合は集計方法を見直した方がよいでしょう。例えばウェイトバック値が4倍になると、特定の回答の影響も4倍になり、結果が偏って拡大推計の信頼性が低下します。
拡大推計を正確に行うコツ
拡大推計の精度を高めるには、適切な手法の選択と実施が不可欠です。ここでは、拡大推計を正確に行うための2つのコツを紹介します。
サンプリング割付を行う

サンプリング割付とは、アンケート実施前に予め属性などのセグメント別にアンケート回収数を設定しておき、規定数に達したセグメントから回収を締め切っていく方法です。拡大推計の前にサンプル割付を設定をすることで、セグメントの偏りを少なくして効果的に調査を進められます。
例えば、引っ越しに関するアンケートを実施する際、調査対象を「関東に住む一人暮らしの10〜30代」に設定したとしましょう。そのまま実施すると回答者の年代に偏りが生じる可能性がありますが、事前にサンプリング割付を設定することで特定の年代への偏りを防げます。
何を基準にサンプリングをするのかは拡大推計で扱うデータによって異なり、特に決まりはありません。年代、性別、居住地などさまざまな要素があります。拡大推計を行う前に予め設定しておかなければ偏りが生じそうな属性を選びましょう。
サンプリングには多様な方法があり、代表的なものは2種類です。1つはサンプル数を均等に指定する「均等割付」で、項目ごとの比較に適しています。もう1つの「人口構成比割付」は、日本の人口構成比など母集団の比率に合わせて設定する方法で、全体の傾向を調べるのに最適です。
均等割付と人口構成比割付の例
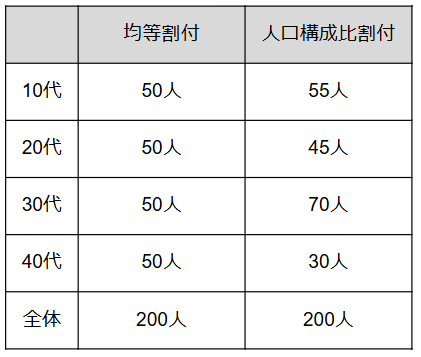
精度の高いデータを集める

拡大推計の精度を高めるもう1つの重要なポイントは、精度の高いデータを収集することです。拡大推計は数値を扱う定量的な方法のため、元のデータが間違っていると正確な推計ができず、全工程が無意味な作業に終わってしまいます。
信用度の高い拡大推計を実施するために、データ収集の際は「Yes/No」「はい/いいえ」などの回答形式を揃えて一貫性を保ち、集計時のミスを防ぎましょう。また、拡大推計の前には回収したアンケート結果を整理し、重複データや無効なデータがないかの確認・修正も必要です。
拡大推計の活用方法
拡大推計は、さまざまな分野で活用されています。ここでは、拡大推計の具体的な活用方法として、弊社の事例を中心に紹介していきましょう。
機械学習による拡大推計

機械学習とは、コンピュータが膨大なデータからパターンやルールを学習し、予測や判断を行う技術のことです。機械学習には「学習」と「推論」のプロセスがあり、拡大推計に活用することも可能です。
例えば、機械学習を用いて「犬」を識別する場合について考えてみましょう。まず、「学習」段階では、コンピュータに犬や犬以外の動物などの情報を与えて犬の特徴を学ばせ、推論モデルを形成します。
続いて、学習したモデルに当てはめて新しい情報を判断する「推論」の段階です。初めて見る画像Aが、犬の特徴に関する推論モデルに近いと判断できれば、「画像Aは犬である」という予測ができます。このような機械学習を応用して、一部のサンプルで「学習」を行い、母集団全体に「推論」を用いることで、母集団に同じ特徴を持つものがどの程度いるのかを予測、つまり拡大推計することができます。
Pontaビッグデータを活用した潜在顧客の構築・分析

共通ポイントサービス「Ponta(ポンタ)」を運営する弊社は、1億IDを超えるPonta会員の属性や行動データを対象にした分析を通じて、企業の課題解決をサポートしています。Pontaビッグデータを活用した拡大推計を行うと、潜在顧客の構築や分析も実施可能です。
例えば、あるクレジットカード会社様は新規客獲得を目指すも、顧客像や訴求内容が定まっておらず、プロモーション施策を立案できない状態でした。そこで実施したのが、Ponta会員の中でカードを利用している人へのアンケートや機械学習による拡大推計、ターゲットの選定です。
利用者やブランドの特徴を探るアンケートを参考に、機械学習による拡大推計で1億人のPonta会員に対し、潜在顧客セグメントを作成しました。これに基づいてターゲットを選定し、対象者に刺さるクリエイティブを制作してプロモーションの支援まで行っています。
事例の詳細は下記をご覧ください。
顧客の価値観を明確化したペルソナマーケティング

ペルソナマーケティングとは、架空の顧客像(ペルソナ)を作成して戦略を立てる手法です。属性などを大まかに設定するターゲットと違い、価値観や趣味まで詳細に設定するため、顧客視点での施策を立案できます。拡大推計を活用すると、精度の高いペルソナを作成可能です。
例えば弊社では、独自のアルゴリズムによる価値観判別ロジックで、企業の顧客像を明確化するペルソナマーケティング支援サービス「PERSONA+」を提供しています。
本サービスの15の価値観クラスターは、Ponta会員5万人への200問以上のアンケートによって抽出した価値観因子を独自構築したものです。これを拡大推計することで、約1億IDのPonta会員の価値観を把握できます。
また、顧客の価値観を把握し、データに基づくペルソナを簡単かつスピーディーに構築可能です。さらに、設定したペルソナに近い価値観のPonta会員に広告配信を行うなど、効果的なプロモーションの実施まで支援いたします。詳しく知りたい方は、以下をご覧ください。
複数業態を横断した購買データの活用
弊社の「Ponta Adsリテール業態横断」においても、拡大推計を活用しています。本サービスは、複数業態を横断した購買データを活用し、拡大推計を通じて効果的なマーケティングを支援するプランです。
1億人超のPonta会員IDに紐づく属性情報や決済・情報などを活用すると、ターゲットに近い層を拡大推計できます。また、横断的な購買データと組み合わせることで、購買の対象者を選定可能です。
さらに、大手プラットフォームやメディアとも連携しており、ターゲットに応じた広告配信のサポートもいたします。精度の高い拡大推計によって効果的にターゲットを設定したい方や、対象者に合ったプロモーションを展開したい方は、詳細をご覧ください。
ロイヤリティ マーケティングは拡大推計を活用して分析からアプローチまで支援します
拡大推計は、身近な場面やマーケティングの場面で幅広く使われている手法です。拡大推計は古くからある方法ではあるものの、コンピュータが発達した現代でも廃れず、むしろビッグデータや機械学習と組み合わせてますます活用の幅が広がっています。
拡大推計を現代の技術と組み合わせると、マーケティング施策に役立つ新しい知見を得ることが可能です。また、拡大推計を応用してデータを有効活用すれば、競合他社との差別化を図り、自社の強みを活かした施策を立案できるでしょう。
弊社はPontaビッグデータを組み合わせた拡大推計の活用により、企業のデータ活用や分析、プロモーションをサポートしています。データの活用方法にお困りの方や、競合の一歩先を行く一手でビジネスを成功に導きたい方は、お気軽にご相談ください。

.jpg)

お気軽にお問い合わせください
詳しくお知りになりたい方はお問い合わせ